-
Linguistics Reimagined

DigitaL aims to foster the application of modern digital and computational methods in the language sciences.
The project is funded by the European Union through the Erasmus Plus Grant "Linguistics reimagined: Applying digital tools in language research" (Project 2025-1-MT01-KA220-HED-000353724) from 2025 to 2027. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency (nor any other funding agencies involved). Neither the European Union nor the granting authority can be held responsible for them.


Last updated on 2026-06-26 14:39.

This website by J.-M. List, J. Nieder and N. W. Hill
is licensed under a CC-BY-NC-4.0 license.
-
About
Background
DigitaL is an interdisciplinary initiative that transforms how linguistics and computer science are taught and practiced. The project creates a unified learning experience that empowers students and researchers to use modern digital and machine-learning tools in language research. Through a hybrid lecture series, expert talks, collaborative meetings, and a student conference, participants develop practical skills in data creation, curation, and contextualization.
Key outputs, including an open-access textbook, research blog, and recorded lectures, promote open science and support early career development. By fostering international collaboration between Malta, Passau and Dublin through innovative teaching practices, the project strengthens digital readiness in higher education and prepares a new generation of linguists for a data-driven research landscape.
Topics of Interest
Data Creation: A crucial step in linguistic research, data creation provides the foundation for meaningful analysis. The project will develop high-quality linguistic datasets with Nathan Hill leading efforts in Automatic Speech Transcription, improving speech data collection through machine-assisted transcription methods.
Data Curation: Ensuring linguistic datasets are structured, standardized, and accessible for long-term research. Johann-Mattis List will lead this area, applying quantitative comparative linguistics to establish standardized workflows, ensuring interoperability across languages, platforms, and disciplines.
Data Contextualization: Beyond collection and organization, linguistic data must be placed within theoretical frameworks. Jessica Nieder will lead this area, integrating computational semantics and machine-learning-driven approaches to enhance linguistic analysis.
Last updated on 2026-06-26 14:39.
This website by J.-M. List, J. Nieder and N. W. Hill
is licensed under a CC-BY-NC-4.0 license.
-
Events
Upcoming Events
DigitaL Talk Series to Continue with Two Talks in June (Passau and hybrid)
The talk series (see a detailed poster with information on how to access remotely here will introduce the three key topics of DigitaL — Linguistic Reimagined in three blocks, each organized by one of the three project partners. Participation will be possible in hybrid mode and in person. To enroll for the talks, please write an email to reima@digling.org in order to obtain the necessary information of how to participate virtually or in person. For more information, see also the entry at the website of the University of Malta.
Passau Talks in June
Talk 1: Franz Xaver Erhard
Date June 16,2026 Time 16:15 CET Venue University of Passau / virtual sphere Speaker Dr. Franz Xaver Erhard Title Scripts, Columns, and Models: HTR Approaches to Historical Tibetan Newspapers Abstract Digitising historical Tibetan newspapers poses challenges that go far beyond the recognition of individual characters. The Divergent Discourses project (AHRC/DFG) has developed a hybrid workflow for Handwritten Text Recognition (HTR) that combines the Transkribus platform with supplementary tools for layout analysis. The presentation introduces Transkribus as a platform for HTR for low resource languages and reflects on both its strengths and the limits it encounters with specialised material such as Tibetan newspapers — whose dense multi-column designs, mixed scripts, and inconsistent typefaces defeat standard segmentation approaches before a single character is ever recognised. To address these limitations, the project has integrated a YOLO-based line detection model trained specifically on Tibetan newspaper pages, treating layout analysis as a research problem in its own right rather than a preprocessing afterthought. The talk shares lessons learned from combining these tools for a script and document type that general-purpose platforms were not designed to handle, and reflects on what this approach makes possible for large-scale historical and discourse analysis of Tibetan-language sources. Talk 2: Kellen Parker van Dam (University of Passau)
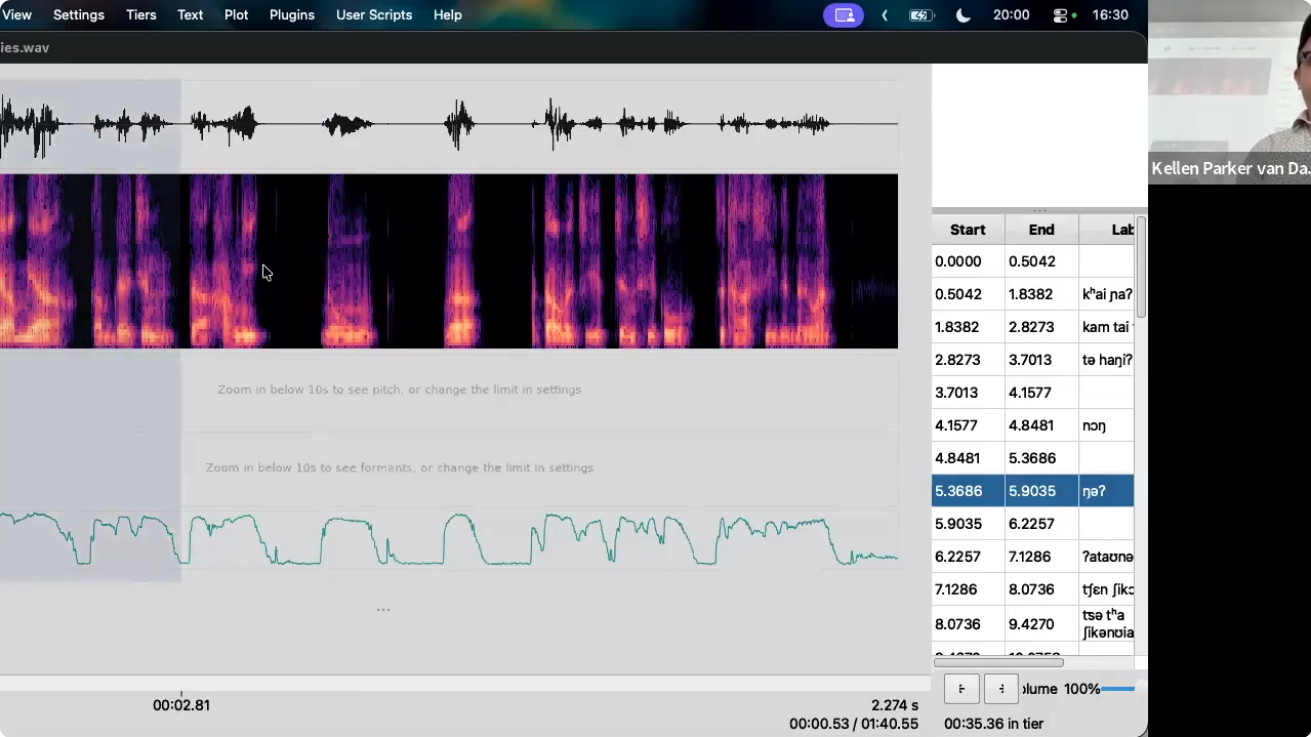
Date June 23, 2026 Time 16:15 CET Venue University of Passau / virtual sphere Speaker Kellen Parker van Dam Title Besra: A tool & workflow for rapid audio/text processing and model training Abstract A major bottleneck in data creation for under-documented languages is the time cost of transcribing texts. It is not unusual for a fieldwork linguist to have many hours of recordings which have not been transcribed. To help in this task, we here introduce Besra, a tool and workflow to help resolve this, allowing linguists to make available this backlog of data. Through the use of a Praat-like transcription tool with a Python-based plugin ecosystem and access to the entirety of the Python Package Index (PyPI), Besra enables rapid creation of transcripts, with built-in tools for ASR model training, forced alignment, formant and pitch calculation, visualisation or data, and extensibility through installed packages and user scripts done entirely in Python. This talk presents the justifications for this tool and the benefits of a Python-focused approach for a wide range of tasks which were previously difficult or inaccessible in more traditional workflows. Malta Talks in April
Talk 1: Claudia Borg (University of Malta)
Date April 14, 2026 Time 17:00 CET Venue University of Malta / virtual sphere Speaker Claudia Borg Title From Words to Meanings Across Languages: How Neural Models Represent Languages Abstract How can a computer represent the meaning of a word? This talk introduces the idea of word representations, starting from familiar linguistic concepts such as collocation, semantic similarity, and polysemy. I will show how modern language technologies use patterns to build representations of words and contexts, and how multilingual models extend this idea by relating meanings across languages. I will discuss what such models can reveal about language structure, variation, and cross-linguistic similarity, as well as their limitations. Talk 2: Harald Baayen (University of Tübingen)
Date April 21, 2026 Time 17:00 CET Venue University of Malta / virtual sphere Speaker Harald Baayen Title Linguistic analysis with word embeddings: methods and examples Abstract Word embeddings are high-dimensional numeric representations of word meaning, derived from large corpora. I will first introduce the core concepts underlying embeddings. I will then show, by means of a series of examples, how one can 'data mine' embeddings for linguistic analysis, using some basic but surprisingly powerful statistical tools. One set of examples will address the semantics of number in inflectional morphology. I will show that the change from singular to plural in semantic space can depend on semantic class (English) or case (Russian, Finnish), or on whether a plural is a broken plural or a sound plural (Maltese). A second set of examples will discuss recent results indicating that embeddings can be surprisingly predictive for the fine phonetic detail with which words are articulated. Past Events
DigitaL Talk Series to Start with Two Talks in February (Dublin and hybrid)
The talk series (see a detailed poster with information on how to access remotely [here](data/poster-talk-series-2026.pdf)) will introduce the three key topics of *DigitaL — Linguistic Reimagined* in three blocks, each organized by one of the three project partners. Participation will be possible in hybrid mode and in person. To enroll for the talks, please write an email to reima@digling.org in order to obtain the necessary information of how to participate virtually or in person. For more information, see also the entry at the website of the [University of Malta](https://www.um.edu.mt/newspoint/upcomingevents/2026/digitallinguisticsreimaginedtalkseries.html).
Dublin Talks in February
Talk 1: Rolando A. Cota Solano (Youtube)
Date February 10, 2026 Time 17:00 CET Venue Trinity College Dublin / virtual sphere Speaker Rolando A. Cota Solano (Dartmouth College) Title Incorporating ASR into Language Documentation Workflows Abstract Transcription of audio and video recordings is one of the main bottlenecks in the creation of corpora for language documentation and revitalization. In this presentation we will discuss the role of automatic speech recognition (ASR) in accelerating this work, as well as new challenges that might emerge when adapting ASR to the documentation workflow. We will discuss examples from three projects to document (i) Cook Islands Māori, (ii) Bribri from Costa Rica, and (iii) languages from Southern Arizona. Talk 2: Michael Bayona
Date February 17, 2026 Time 17:00 CET Venue Trinity College Dublin / virtual sphere Speaker Michael Bayona (Trinity College Dublin) Title Speech Technologies for Under-Resourced Languages: From Development to Application Abstract This talk introduces recent speech technologies with a focus on under-resourced languages, using low-resource ASR as a central case study. It will cover the basic pipeline from data and modelling choices through evaluation and deployment and will point to approaches that are particularly useful when training data are limited. Examples will be drawn from work on Philippine languages, with the aim of keeping the discussion concept-driven and accessible to an advanced undergraduate linguistics audience. Past Events
Last updated on 2026-06-26 14:39.
This website by J.-M. List, J. Nieder and N. W. Hill
is licensed under a CC-BY-NC-4.0 license.
-
Resources
Publications
Lectures
Talks
Our open talk series started in February. The talks can still be inspected on YouTube, they are listed below.
Kellen Parker van Dam (University of Passau) -- Besra -- a tool & workflow for rapid audio/text processing
Franz Xaver Erhard (University of Leipzig) -- HTR Approaches to Historical Tibetan Newspapers

Harald Baayen (University of Tübingen) -- Linguistic analysis with word embeddings: methods and examples

Claudia Borg (University of Malta) -- From Words to Meanings Across Languages: How Neural Models Represent Languages

Michael Bayona (Trinity College Dublin) -- Speech Technologies for Under-Resourced Languages

Rolando Coto (Dartmouth) -- Incorporating ASR into Language Documentation Workflows

Tutorials
Software
Data
Last updated on 2026-06-26 14:39.
This website by J.-M. List, J. Nieder and N. W. Hill
is licensed under a CC-BY-NC-4.0 license.